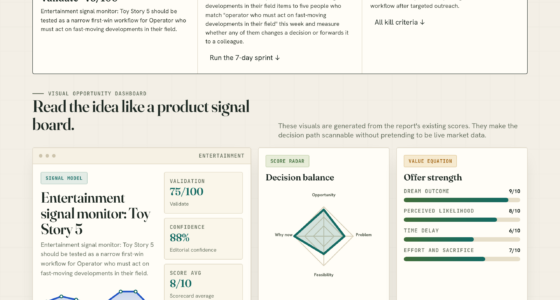
📊 Full opportunity report: Data: The One Thing You Can’t Rent on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
The AI industry faces a new bottleneck: data that cannot be rented or easily acquired. With public data exhausted and legal restrictions tightening, access to unique, verified human data has become critical, reshaping industry power dynamics.
In 2026, the AI industry has shifted its focus from renting compute and web-scraped data to acquiring rare, verified human data that cannot be easily rented or duplicated, marking a fundamental change in how models are trained and who controls the industry’s core assets.
Recent legal actions and market trends confirm that the era of freely scraping data from the internet is ending. Notably, Anthropic’s $1.5 billion settlement over copyright claims signifies a move toward licensing-based data access, making data a costly, fenced resource. This legal shift is reinforced by ongoing cases like the New York Times’ dispute with OpenAI, which highlight the move away from free data to paid licensing regimes.
Simultaneously, the industry is increasingly relying on high-value, verified human data—such as expert annotations, proprietary datasets, and sensitive information—that cannot be easily rented or replicated. This has elevated the importance of specialized expertise, with companies investing heavily in acquiring exclusive data sources, often at significant cost. The move toward expertise-driven data collection has created new industry chokepoints, favoring well-funded incumbents and marginalizing startups unable to afford such data.
Furthermore, the scarcity of public internet data, estimated at around 300 trillion tokens, is nearing exhaustion, with projections indicating full utilization between 2026 and 2032. Synthetic data and more efficient algorithms help extend datasets temporarily but do not replace the need for fresh, human-verified data, which remains the most valuable resource for model accuracy and reliability.
Data: The One Thing You Can’t Rent
The free part of “all human knowledge” is running out. As compute and models commoditize, the corpus you can’t replicate becomes the moat — so data is being fenced, priced, and, in places, treated as a national asset.
Data was supposed to be the abundant input. It’s the scarce one. It’s also the chokepoint you can actually own — so guard your proprietary data, and don’t hand it to a provider who can become your competitor (the lesson everyone fled Scale to learn). Nations: license it like Ukraine — keep the model, keep the leverage.
Why Data Fencing Reshapes AI Industry Power
The transition from open, free data to fenced, licensed data fundamentally alters industry dynamics. It creates barriers to entry for startups and increases reliance on large, resource-rich companies that can afford licensing fees. This shift consolidates power among incumbents, making data ownership a critical competitive advantage. Additionally, the focus on rare, verified human data raises stakes for data security, intellectual property rights, and international regulation, impacting how AI models are developed and deployed globally.
verified human data annotation services
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Legal and Market Shifts Drive Data Scarcity
Historically, AI models trained on freely available web data, with companies scraping content without significant legal repercussions. However, in 2026, landmark legal cases, such as Anthropic’s copyright settlement and ongoing litigation involving major publishers, have established that free scraping is no longer permissible without licensing. This legal precedent has prompted a shift toward paid data access, favoring large corporations with the resources to negotiate and pay for proprietary datasets.
Simultaneously, the industry is moving away from cheap, bulk labeling tasks performed by low-cost contractors, toward sourcing rare, high-quality data generated by experts in specialized fields. This evolution reflects the increasing complexity of AI models that require domain-specific knowledge, making data acquisition more expensive and exclusive.
As public internet data approaches exhaustion, companies are turning to synthetic data, proprietary collections, and expert-generated content, which are more costly but also more valuable for training advanced models with reasoning and reasoning capabilities.
“The landmark settlement confirms that using pirated content for training is no longer acceptable; licensing and fair use are the new rules.”
— Legal expert involved in Anthropic case

JVWKPU Precision Label Applicator for Jars, Bottles & Candle Vessels, Manual Label Placement Tool for 0.5–5 Inch Containers, Professional Labeling Tool for Small Business & Handmade Products
Perfectly Straight Labels, Every Time: Achieve professional, centered, and level label placement on jars, bottles, and candle vessels….
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Data Monopoly and Regulation
It remains unclear how international regulation will evolve to address data fencing and licensing, and whether smaller players will find alternative ways to access or generate valuable data. The long-term impact of legal rulings on open data initiatives and the potential for new data-sharing frameworks are still developing.
proprietary dataset licensing platforms
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Future Industry Trends and Data Acquisition Strategies
Expect continued legal and market developments that reinforce data fencing, with large firms expanding their proprietary datasets and startups seeking innovative, cost-effective ways to acquire or generate high-quality data. Regulatory responses at national and international levels may influence data access and ownership, potentially reshaping the competitive landscape further.

AI Workflows for Dental Office Managers: ChatGPT Playbook to Automate Patient Scheduling, Streamline Insurance Verification, and Eliminate Administrative Burnout
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Why is data now more valuable than compute or algorithms?
Data, especially verified and rare human data, is what truly differentiates models. As public data becomes exhausted and legal restrictions tighten, access to exclusive datasets determines model quality and competitive advantage.
How does legal action impact the availability of training data?
Legal rulings, like the Anthropic settlement, are establishing that free scraping without licensing is no longer permissible, leading to a shift toward paid licensing and proprietary data sources.
Can synthetic data replace real human data in training?
Synthetic data can supplement training datasets and improve efficiency, but it carries risks of errors and model collapse if overused, making real, verified human data essential for high-stakes applications.
What does this mean for startups trying to compete in AI?
Startups face higher barriers to access high-quality data, as licensing costs and data fencing favor established companies with deep resources. Innovation may increasingly depend on developing new data generation or acquisition methods.
Source: ThorstenMeyerAI.com