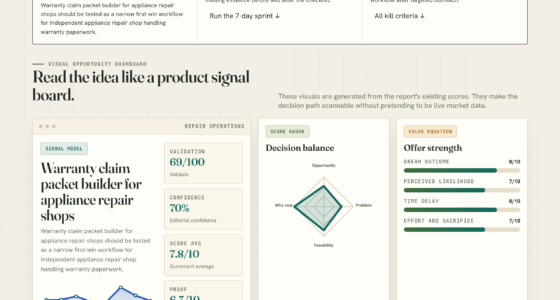
📊 Full opportunity report: Mac vs GPU Tower for Local LLMs: The Heat-and-Noise Tradeoff on ThorstenMeyerAI.com — validation score, market gap, and execution plan.
TL;DR
This article compares Mac Studio and GPU towers for running local large language models, focusing on heat, noise, capacity, and performance tradeoffs. The choice depends on model size and workload priorities.
Apple Silicon-based Macs, such as the Mac Studio with M3 Ultra, offer near-silent operation and low power consumption for local large language model inference, contrasting sharply with GPU towers that generate significant heat and noise.
The core difference lies in architecture: GPU towers prioritize memory bandwidth, delivering higher throughput for models fitting within VRAM, with RTX 5090 cards reaching approximately 1,792 GB/s. In contrast, Macs leverage unified memory capacity, allowing them to load larger models (70B+ parameters) that do not fit in GPU VRAM, albeit at slower speeds.
GPU towers, especially with multiple GPUs, produce substantial heat—single RTX 5090 cards draw around 575W, with dual setups exceeding 800W—necessitating complex thermal management and noise control measures. Conversely, Macs operate with minimal heat output, drawing a fraction of that power, resulting in near-silent operation suitable for continuous use.
The decision hinges on workload characteristics: towers excel in throughput for models that fit in VRAM and in CUDA-based fine-tuning, while Macs excel at running larger models that surpass GPU VRAM limits, with the tradeoff of slower inference speeds.
Mac vs GPU tower
for local LLMs.
What if you sidestep the heat entirely with a different kind of machine? A tower is a high-bandwidth furnace you spend five levers quieting. Apple Silicon is near-silent by design — but asks for different tradeoffs. Match your priority in Part 2.
Put the loud, hot machine where its noise doesn’t matter, and the quiet one where you do. SSH into the tower when you need raw power; let the Mac handle everything else, silently.
Why Heat and Noise Are Critical in Hardware Choice
The heat and noise profiles of these machines directly impact user experience, especially for continuous, on-desk operation. GPU towers require ongoing thermal management, fan tuning, and space considerations, whereas Macs offer plug-and-play simplicity with silent operation. The choice affects not only performance but also comfort, noise pollution, and energy consumption in a workspace.
Understanding these tradeoffs helps users select the right hardware based on workload size, latency needs, and environmental constraints, making this comparison essential for practitioners deploying local AI solutions.

Apple 2023 MacBook Pro with Apple M3 Max chip, 16-inch, 48GB RAM, 1TB SSD, Space Black (Renewed)
SUPERCHARGED BY M3 PRO OR M3 MAX — The Apple M3 Pro chip, with a 12-core CPU and...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Architectural Tradeoffs in Model Inference Hardware
Historically, GPU towers have been the standard for local AI due to their high memory bandwidth and CUDA ecosystem, supporting fine-tuning and training. However, their thermal footprint and noise levels have driven interest in alternative architectures.
Apple Silicon's unified memory architecture allows for large models to be loaded and run on a single device, shifting the paradigm from raw throughput to capacity and power efficiency. This shift is increasingly relevant as model sizes grow beyond VRAM limits of consumer GPUs.
"The heat-and-noise dimension is one of the sharpest differences between Mac and GPU tower choices for local AI."
— Thorsten Meyer

Corsair Vengeance i8300 Gaming PC – Liquid Cooled Intel® Core™ Ultra 9 285K, NVIDIA® GeForce RTX™ 5090 GPU, 64GB Dominator Titanium RGB DDR5 Memory, 2+4TB M.2 SSD – Black
GeForce RTX 50 Series Graphics Card: Powered by NVIDIA Blackwell, GeForce RTX 50 Series GPUs bring game-changing AI...
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Unresolved Questions About Long-Term Performance
It remains unclear how future developments in Apple Silicon or GPU architectures will shift these tradeoffs, particularly regarding model scaling, software ecosystem maturity, and thermal management innovations. The long-term upgradeability of Macs versus GPU towers is also an open question.

LLM Inference Architecture in Simple Terms : Running Large Language Models: The Complete Guide to Hardware, VRAM, and Inference Optimization
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Next Steps in Hardware Development and User Choice
Expect ongoing improvements in Apple Silicon's performance and capacity, potentially narrowing the gap for larger models. Meanwhile, GPU manufacturers may enhance thermal efficiency and noise reduction. Users should monitor these developments to inform future hardware investments based on workload needs and environmental preferences.

Mastering AI Workstations for High-Performance Computing: Your Guide to Configuring, Optimizing, and Harnessing the Power of AI-Ready Workstations for Maximum Productivity
As an affiliate, we earn on qualifying purchases.
As an affiliate, we earn on qualifying purchases.
Key Questions
Can a Mac run large language models as effectively as a GPU tower?
Macs can run larger models that don't fit in GPU VRAM, but generally at slower inference speeds. The choice depends on whether capacity or throughput is the priority.
How significant is the heat and noise difference in practical terms?
GPU towers produce substantial heat and noise, requiring active thermal management, while Macs operate quietly and with minimal heat, which can be a decisive factor for continuous, on-desk use.
Will future Mac hardware close the performance gap with GPU towers?
Potential hardware and software advancements could improve Mac performance, but currently, GPU towers still lead in maximum throughput for models that fit VRAM.
Is upgradeability a concern for Mac users?
Yes, Macs are fixed at purchase with no GPU upgrade options, whereas GPU towers support adding or replacing cards, offering more flexibility for scaling performance.
Which hardware is better for training models, not just inference?
GPU towers are generally better suited for training and fine-tuning due to their native CUDA ecosystem and higher throughput capabilities.
Source: ThorstenMeyerAI.com